
Here at Digivante our monolith legacy platform grew over years and years of organic growth in response to various customer requests and needs. For sure that’s a familiar story for many tech-based businesses. But the problem is that over time, documentation and general knowledge of the system fade as key people leave and the challenge becomes how do you effectively maintain it?
When you couple this with the system being designed as an application to be running on a single web server you also realize that you have deep rooted issues with scaling your app, even if your database can handle it and you could throw more money at the hardware. We have managed to make the legacy system very stable, and it performs well, but it would not keep up with the ambitious growth targets and new product ideas that have. We want to grow the business, but the goal isn’t just to sysadmin more servers.
The other problem arising from a single server architecture is that it doesn’t nicely cater for our user base. Our crowd of testers are very geographically dispersed and could often be in locations that require many hops over slow connections to reach our server based in London, UK.
Additionally, having your business-critical application developed on an antiquated framework that developers are no longer interested in is a risk. Whether you are trying to expand your team and hiring new talent, it’s harder because of it. Or if you want to think about it in terms of the “bus factor”, this should be something on your business continuity risk register.
The business has been convinced for a long time that they needed a new system. Various attempts have been made to address this, but the results simply didn’t materialize quick enough with the Big Bang waterfall mentality – which was still inherent even when “working in Agile”.
What we need from a new platform
Given the above challenges and thinking about our users and the business, we set out to determine what we need from our new platform.
- A new platform to release new features on
- Compatibility and interoperability with the legacy system
- Scalability of the service
- Improved access speeds for our users
- Fresh tech stack that software engineers find appealing
- A more up to date approach to deployments
- Security and access controls
In other words, quite a few different objectives to consider.
The new tech stack
We’re an AWS shop, and we quite like it, so we weren’t planning any big changes there, The goal is that we can have the legacy and new systems speak to each other.
We wanted to split the front end and the back end. Clearly, we weren’t after just a new PHP framework. For some of the projects, we had played around with Angular and built APIs, but the experience and the results were not to the liking of the devs, so it was rather quickly decided that we would be using React. Looking at the market, this also seemed like the smart bet from a hiring perspective – but that may of course differ from area to area. There are clearly pros and cons to both which you can read about elsewhere, but we felt React was going to fit our needs better.
For the back end, we wanted to ditch the traditional REST API development and wanted to be more flexible and were convinced that it made sense to move to GraphQL on node.js. So far this has worked very well for us and, especially as an internal app, this seemed to speed development up.
REST APIs still make total sense when you are working with external users and you want to provide structured access to resources, just like we do with our Digivante API, which allows our clients to engage with our services. Internally, however, we get much more flexibility and better efficiency from working with GraphQL.
Multiple applications in one
Our main platform has always had three distinct user types with very different goals and activities associated with them. These three different user types are our clients, internal admins and of course the very large crowd of testers. The different user types govern what they can see and access at a high level before looking at the individual permissions and access levels. In our “monolith” this has of course led to complicated structures where a lot of the pages are somewhat shared, but some sections and functions are only available to one user type, for example.
Overall, our decision was that in our new design we wanted to split the application into three so that we could achieve total separation of the users and their application with security and speed in mind. We felt that it would be advantageous to build individual apps and only have the user-relevant code bundled, especially for the front-end app. Clearly, we also have some functions that are very similar or indeed the same in display properties or data structures, so code reuse and sharing was an important factor.
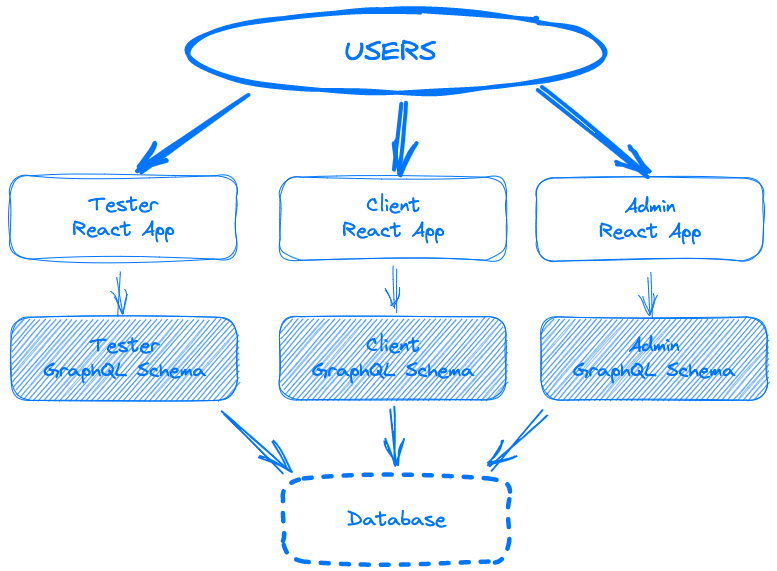
Our Apollo GraphQL (node.js) is set up to serve three different end points, each of which has their own schema definitions and auth requirements. What this means is that already at a higher set type level we can gate keep and allow only specific authenticated user types to their own relevant schema. This setup allows us to set up common resolvers that are surfaced in different schemas, or indeed have ones that are only available in others.
With the React front end we decided to go with a monorepo approach. This may be a little unusual, but we all wanted to work in a single GIT repo for this rather one per application. This allows us to structure the code base such that we can have shared components in one folder and reuse them in each of the user specific applications that are all setup in their own sub folders. The build process is set to build the JS bundles for each app individually from their own set of configs. They also of course have their own environment settings and are each configured to access their own version of the GraphQL backend.
Deployment, speed and scalability
Like I said, we’re working on AWS and wanted to keep things simple from that point of view – so the decision was simple in that we wanted to use the same infra that we were used to, coupled with a few new toys.
We already migrated our existing system to be behind an ALB and our DNS is in Route53, so managing a new part of the system was going to be “easy enough” from that perspective.
We already had CloudFront configured for the legacy system to speed up the delivery of static assets from the system running on an EC2 – but in this case we really didn’t want to use EC2s for anything at all, and configured S3 buckets as the source of the files for the new CloudFront distributions. The advantage of this setup is that we’re not running any servers to deliver the front end, our build pipeline automatically deploys each app to S3, and CloudFront is set to deliver this efficiently to all our users around the world. The CDN ensures that the entire app for them is delivered from a speedy location close to the end user.
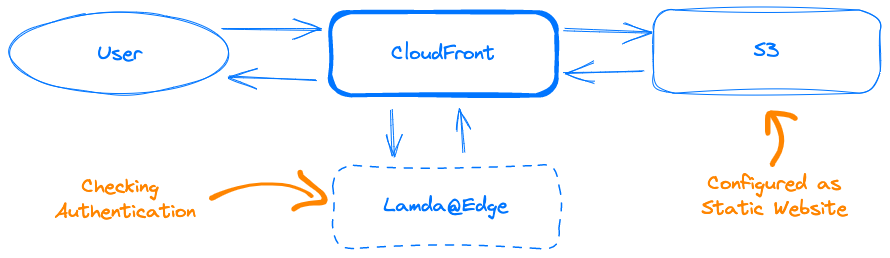
There are a few tricky components in this setup, such as setting up the S3 as a static website host, but not making it available to all, and using Lambda@Edge to handle authentication to check if the user is authorized to download the app bundles. Honestly though, the most annoying thing about the setup overall is that because of the application split you end up with three separate distributions to configure for each environment such as production, staging, etc.
We use Docker for our local environments and felt that it was a natural progression to get our pipeline to build the same images and push them to Elastic Container Registry. The pipeline also triggers the Fargate service to swap over to the latest tagged image. Fargate automatically handles the traffic switch from old containers to new, and we are also in control of how many containers are defined to run in the cluster. It also monitors the health of each of them and replaces them if needed – this clearly achieves our goal of easy scalability for us as well, as we can also in the future couple the scaling up and down of the service to the performance metrics.
Our Aurora database was always a replicated setup, but in the new GraphQL server we’ve been clear in separating the query resolvers to use a read-only end point for the RDS cluster and mutations to use the write endpoint. This enables us to keep a lower pressure on the master database and we can scale the replicated read nodes, should we need to.
How it’s secured
One of the tricky parts in our setup was the desire to keep the front-end apps entirely private but at the same time easily available. E.g., we did not want to have the internal facing app front end code available to all – even if it was hard to decipher anything from the JS bundles. This can be somewhat of a challenge because CloudFront is of course meant to just deliver content to everyone – and for it to work nicely with a React SPA application the S3 also needs to be set up as a static website host. This however, normally means that the application is available to everyone.
So, how’s it secured? S3 is set to look at secret headers injected by the CloudFront distribution, so it only responds if it is the relevant CloudFront distribution making the request. Our login on the legacy app is set to use the AWS SDK to generate CloudFront signed cookies to authorize specific user types to access their new front-end app and these cookies are inspected by the Lambda@Edge functions. Whenever a request is made to CloudFront that fails the authentication (no cookies, old session, wrong user type, etc.) then the user is redirected to the login form elsewhere.
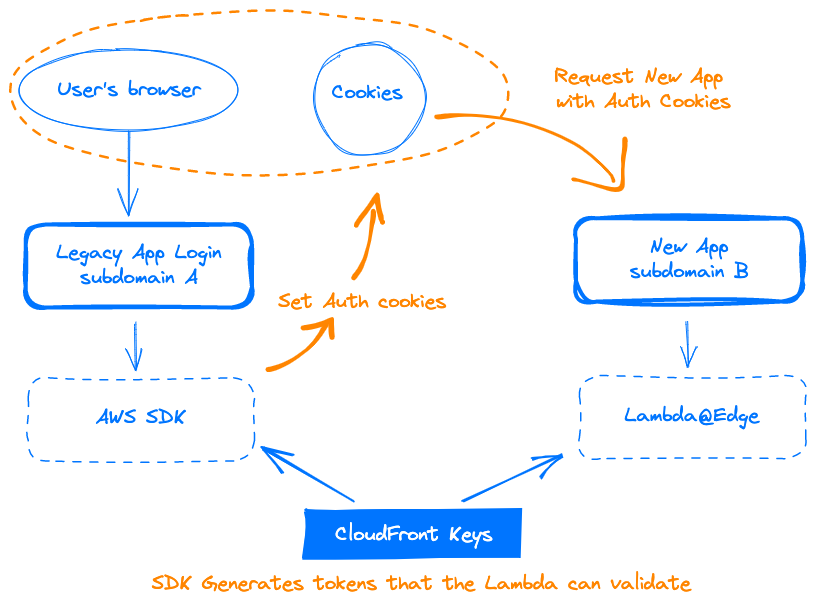
This feels like a little bit of an elaborate setup, but it does allow us to bypass using the more traditional server setups, while totally blocking access to the front-end assets to specific applications – and that’s quite neat.
Old and new together
Our goal from the beginning was to forget the Big Bang approach and have both the legacy system and the new platform work from the same data source, so that we could keep working on both, and eventually move things over feature by feature – while developing new things only on the new platform and dedicating a chunk of tech debt time to continually chip away at the migration as well.
To achieve this; both the server-side legacy app and the new GraphQL connect to the same Aurora RDS. They work behind the same user login but on separate subdomains. We upgraded the look and feel of the legacy app template to match the new one and now the users can navigate between them without any real visual change.
What this gives us is the possibility of having two systems that can work simultaneously and because the underlying data is the same, we have the flexibility to direct users (or even only a subset of them) between the old and new platforms for specific things we want to test. It also means that when we release some iterations for early feedback, we can still have the robust legacy version for the users to fall back on should they need to.
One of the largest challenges in the system design is that we need to always consider the data structures involved, and any changes need to be backwards compatible or be implemented in both systems carefully.
A robust system
Avoiding the Big Bang approach gives us the confidence in releasing and testing new features, while ensuring that the tried and tested features currently in use can continue to serve our users.
The new design also inherently addresses the challenge of delivering our app in speedy fashion to our very distributed user base and slowly migrates us away from the need from managing old-school servers. As discussed, we will also benefit from a much-improved scaling capability to respond to any peaks in usage in a cost-effective manner.
Likewise, the further requirement for improved security and user separation is taken care of in the way we’ve split the application. Furthermore, the modern deployment pipelines and a generally far more up to date tech stack will help with both the job satisfaction and engagement from the current developers, and indeed help with finding new talent in the future.
I rather like this approach and while it’s early days, it feels like we now have the beginnings of a robust system that is working hand in hand with the legacy system. Over time, it will grow as we continue with the migration and work through redefining our user experience and reimagine what we need as a business.




